1 ABS & Introduction
1.1 Abstract
对象:streams, time-series data, sequence
异常检测难点:real-time processing
NAB是一个测试评估针对流数据的异常检测算法的开源工具。
理想的异常检测器
检测到所有出现的异常
尽早检测出异常,最好在人们看到异常之前
no FP 不误报
实时检测、没有前瞻(不看前面的数据)
自动化检测、无人工调节
- 适用性广泛,具有泛化性
1.2 Intro
静态基准不适合用于实时性算法。Precision和Recall无法反应出早检测这个效果。人工划分训练集测试集不适合流场景。NAB设计了新的评价标准,整合了各类数据集。其他数据集还有the UC- Irvine dataset ,Yahoo Labs。本论文比较了HTM、Skyline、与Twitter的两种方法Twitter 方法,翻 (AnomalyDetectionTs and AnomalyDetectionVec. )。
2,NAB scoring
2.1 基础
异常定义:We define anomalies in a data stream to be patterns that do not conform to past patterns of behavior for the stream. 包括空间异常和时间异常。
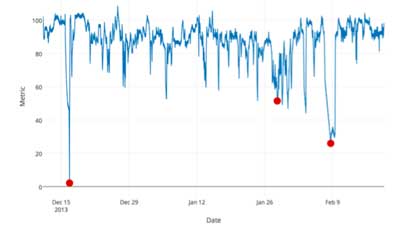
Dataset:范围从IT指标(例如网络利用率)到工业机器上的传感器再到社交媒体聊天。我们还包括一些人工生成的数据文件,用于测试尚未在语料库的真实数据中表示的异常行为,以及几个没有任何异常的数据文件。当前的NAB数据集包含58个数据文件,每个文件具有1000-22,000个数据实例(github里有)
标记异常:按一定规则,标记ground truth label
2.2 算法
算法核心三个方面:anomaly Window,the scoring function,application Profiles(配置文件)
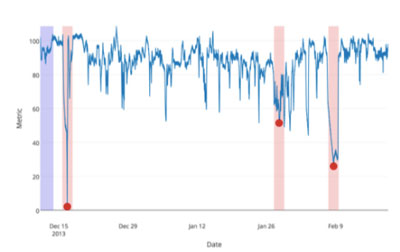
2.2.1 异常窗口
异常窗口是代表一系列以真实异常标签( a ground truth anomaly label )为中心的数据点。
异常窗口的作用是判断真假检测,检测在窗外的话是FP。
评分函数基于窗口识别、加权TP,FP,FN。前面紫色部分只用来初始学习,不需测试。
1,窗口内最早的TP检测被计分,其他忽略。
2,sigmoidal scoring function 给早检测的TP高分。给FP负分数。
3,窗口大小 = 10%*总数据长度/异常数量。实验测试了5% - 20%,由于缩放评分函数,这个百分比对最后结果不敏感。
application profile配置:FN对工业机器来说会造成损失,FP要求技术人员查看。(对监视数据中心中各个服务器状态的应用程序可能对误报的数量敏感,并且由于大多数服务器群集都相对容错,因此偶尔会遗漏异常情况很好。)因此配置文件用于:对于TP,FP,FN和TN,NAB应用与每个配置文件相关的不同相对权重以获得每个配置文件的单独分数。
2.2.2 计算过程
1,配置权重$A$
$D$ 是数据集,$Y_d$是数据 $d$ 中被检测出来的异常。$f_d$表示没有检测到任何异常的窗口数量,
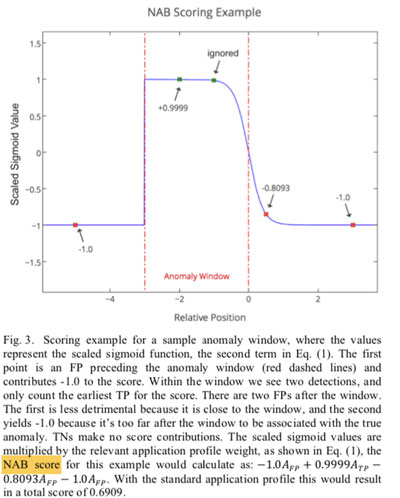
2,单个窗口的得分计算
图中TP:早检测则,增加NAB score;点2:早检测的TP,贡献+0.999 。
FP:减分(窗外后面的FP的减分更大);点1:FP,贡献-1,点4:权重为-0.8093是根据$\sigma^{A}(y)$得到的。5:5更有害,因此5贡献-1。
FN:完全没有检测到,减分。
总的来看这个窗口的得分就是:$−1.0A_{FP} + 0.9999A_{TP} −0.8093A_{FP} − 1.0A_{FP} $ ,公式是:
$\sigma^{A}(y)$中,y表示是检测在异常检测窗的相对位置,参数被设置为窗口右侧,$\sigma ( y = 0.0 ) = 0$。
3,一个数据文件的得分计算
得分是每个检测的得分+错过的Window
4,一个异常检测算法对所有数据集的得分
5,归一化这个算法的分数,normalized NAB score
完美检测器检测到所有TP,无FP。NULL检测器就是没有检测到任何异常。
2.2.3 其他
HTM算法,Skyline统计算法,Twitter统计算法等
每个异常检测器输出是0-1之间的分数,使用固定阈值对分数进行阈值处理,以检测异常。 NAB包括自动爬坡搜索,用于为每种算法选择最佳阈值。其中要最大化的目标函数是NAB评分函数。一个阈值针对所有的数据集dataset(The detection threshold is thus tuned based on the full NAB dataset)。
3 result
见github首页
一些小结论
1,HTM和Skyline对漂移适应得更快
2,HTM和Skyline各自也有误报但HTM可以早检测(3h,机器温度传感器数据)
3,行为的时间变化通常先于容易检测到的大变化(做提前检测)。
Reference
1,Lavin A, Ahmad S. Evaluating Real-Time Anomaly Detection Algorithms—The Numenta Anomaly Benchmark[C]//2015 IEEE 14th International Conference on Machine Learning and Applications (ICMLA). IEEE, 2015: 38-44.
2, https://github.com/numenta/NAB 很好的学习项目

