1, Numenta的HTM简介
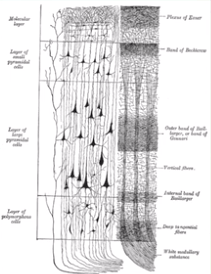
Hierarchical Temporal Memeory(HTM,层级时间记忆,皮质学习) 是一种基于脑神经科学来模拟大脑进行学习和信息处理的神经网络。新皮质就是大脑里褶皱的皮层部分(图1),这只有哺乳动物有。将皮层纵向切开,不论是视觉还是听觉部分,切开后的结构是相似的(图2),很有可能大脑处理不同信息的方法是类似的。
新皮质分化为很多个区域(region,图3),这些区域通过神经纤维连接。这些区域以层次结构的方式连接在一起。低层级信息收集基础信号,经过不同层级逐渐加工,提取并理解更抽象信息,更高级的话或许可以关联到想法、事物活动等信息。这个有点类似卷积神经网络,低层级的网络提取图像边界等信息,高层级的网络识别物体类型等等。
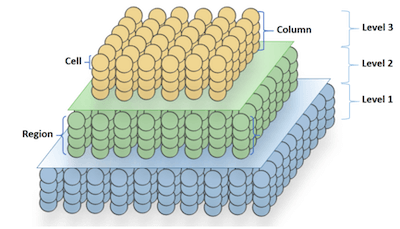
目前,Numenta的HTM设计介绍讲解主要针对一个区域,即一层(图3,如黄色层),说明其数据输入方式,数据表征方式,神经元激活,以及时间记忆表示方式。HTM大概的原理是,首先将输入的数据编码为0、1稀疏数组,将这些稀疏数组经过空间池化转换为稀疏分布表征(SDR),然后时序记忆,建立突触,存储信息,进行预测等。
2, 数据输入
数据输入一般有数字,日期,温度等,将这些数据编码为01稀疏数组(bit数组)。这在计算机领域十分常见,如一个字符的ASCⅡ表示,使用8bit表示的。n个bit可以表示$2^n$容量(capacity)的信息,bit数组可以有许多运算,与或非与异或等等。
在HTM里,稀疏的每一个1可能表示了一个信息。在通过稀疏bit数组的压缩存储(只存1的下标位置),可以表示非常多的数据信息了。
3, 空间池化Spatial Pooler
3.1 稀疏分布表征 SDR
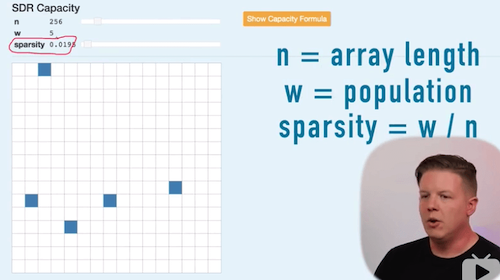
稀疏分布表征(SDR)是空间池化的结果,通俗来看有点像大脑的数据结构,我们先看看SDR的一些特性,如图。计算SDR的容量:
也就是说可以表示这么多的信息量。
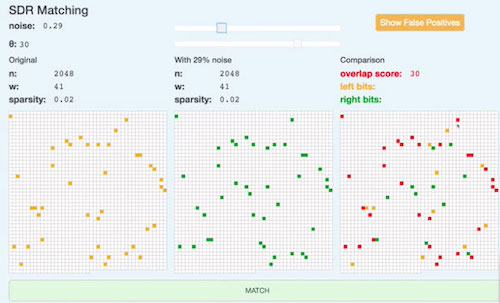
1,SDR的一些基本运算。overlap交集,两个SDR交起来,相同的激活的bit越多,表明这俩SDR越相似。判断俩SDR是否匹配,可以设置一定的阈值。当俩SDR overlap之后,交集bit $>=\theta$ (阈值),则俩SDR匹配。
2,SDR的噪声容忍度(noise tolerant)强。在下图中,选取29%的比例翻转bit的值,对比两个SDR,重叠分数为30。当30大于等于$\theta=30$ 则匹配。意思是说如果俩SDR是原本一致,就算其中一个SDR不完全准确有噪声,则还是会匹配上的。当然也有可能确实两SDR不一致,但又因为噪声导致其匹配上了,这样的误报可能有,但是概率很低 $FP = 交集的基数 / 原始SDR的n w的组合数 $
3.2 SDR的重叠集
如果俩同样大小的SDR(即$n,w$ 分别相等),所有bit匹配,则匹配的SDR必然跟原SDR一模一样,就只有一个。那如果降低匹配阈值 $\theta$ ,当相同激活的bit数目为$\theta$时,可以有多少个SDR与原SDR相匹配呢? 这是个排列组合问题。
相匹配的SDR,左边从原SDR里$w$里选出$\theta$个bit来激活,这是俩SDR相同激活的bit。右边从原SDR里没有激活的$n-w$ 个bit里选出 $w-\theta$ 来激活即可。若 $n=600, w=40, \theta = 39$,算一算可以有 $40 * 560$个不同的SDR与原SDR匹配,是不是很多呀。
这有个好处就是,SDR可以表示很多相似的信息,而且可以直接通过俩SDR的交集来判断是否相似,误报率也很低。
3.3 SDR栈
随着时间序列值逐步产生,即SDR也逐步产生。我们模拟看到SDR进行匹配的过程。new SDR与栈里的SDRs匹配,看看之前是不是见到过。匹配的SDR会有很多重叠的bit。
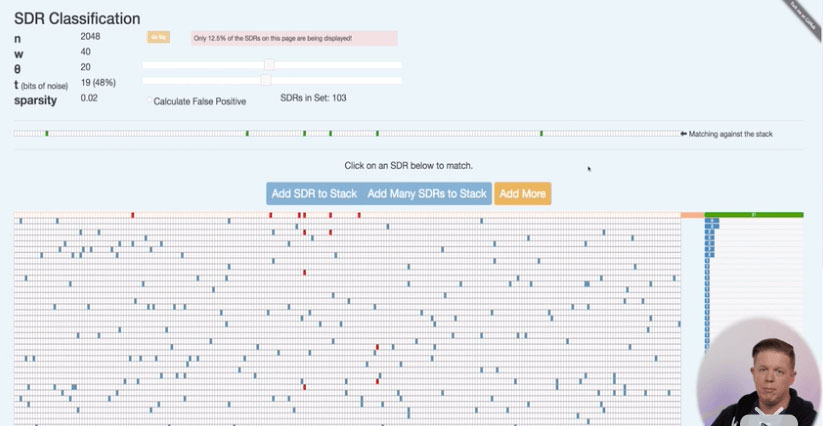
为了加快计算,之前的所有SDR采用Union合并到一起进行匹配。其实由于$n$很大,错误匹配的概率还是很小的。
5, 时序记忆 Temporal Memory
6, 总结
参考
3, Ahmad S, Lavin A, Purdy S, et al. Unsupervised real-time anomaly detection for streaming data[J]. Neurocomputing, 2017, 262: 134-147.

