1 论文中实验
1.1 点云分类classification
数据集:ModelNet40,12311CAD模型,40个类别,9843个训练,2468测试。
我们根据网格区域对网格表面上的1024个点进行统一采样,并将其标准化为单位球体。
数据增强:1,沿上轴随机旋转对象(随机旋转 or 旋转某一角度)。2,通过具有零均值和0.02标准偏差的高斯噪声使每个点的位置抖动来动态地增加点云。
对比实验,table1中SPH[11],3DShapeNets[28],VoxNet[17],Subvolume[18],LFD[28],MVCNN[23](这个的平均每个类别的准确率达到了90.1%,很好诶)与我们的基模型(卷积+最大池化+全连接),PointNet(总体分类准确率89.2 %)的分类准确率比较。
比MVCNN的效果差可能原因是:认为这是由于可以通过渲染图像捕获的精细几何细节的丢失。
1.2 点云零件分割
3D对象零件分割零件分割是一项具有挑战性的细粒度3D识别任务。
数据集:对来自[29]的ShapeNet零件数据集进行评估,该数据集包含16个类别的16,881个形状,总共标注了50个零件。
我们将零件分割公式化为每个点的分类问题。 评估指标是按点计算。 对于类别C(如杯子)的每个形状S(杯柄与内杯),要计算形状S的mIoU:如果groundtruth(真实标记)和预测点的并集为空,则将零件IoU计为1。然后,我们对类别C中所有零件类型的IoU进行平均,以得到该形状的mIoU。 要计算类别的mIoU,我们对该类别中所有形状的mIoU取平均值。
Table2,我们报告每个类别,并表示IoU(%)得分。 我们观察到平均IoU改善了2.3%,我们的网络在大多数类别中都超过了基本方法。
1.3 场景语义分割
零件分割网络扩展到场景语义分割。其中点标签成为语义对象类(semantic object class),而不是对象零件标签(object part label)。
数据集:斯坦福3D语义分割数据集上进行了实验[1]。 数据集包含来自6个区域(包括271个房间)的Matterport扫描仪的3D扫描。 扫描中来自13个类别(椅子,桌子,地板,墙壁等,加上混乱)的每个点都有语义标签进行标注。
为了准备训练数据,首先按房间来划分points,然后将房间采样为面积为1m x 1m的块。我们训练PointNet的分割segmentation版本以预测每个块中的每个点类。
在训练时,我们会在每个飞行块中随机抽取4096个点。在测试时,我们对所有方面进行测试。我们将我们的方法与使用手工制作的点特征的基线进行比较。基线提取相同的9-dim局部特征和三个附加特征:局部点密度,局部曲率和法线。我们使用标准的MLP作为分类器。结果显示在表3中,其中我们的PointNet方法明显优于基线方法。
2 我的理解
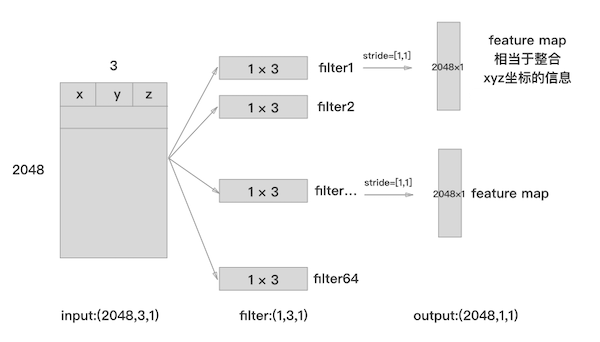
1,卷积的过程
如何对点进行卷积,提取关键点(信息点)
在卷积的时候,把点云看做是(2048,3,1)的一张灰度图来进行卷积计算。但第一步的卷积核大小是(1,3) 是对点进行计算,提取他的特征点。后续的卷积卷积核也是(1,1)的,也是提取一些关键点。
2,对称函数 max pool的作用
解决无序性问题(为什么可以解决无序性)
原生的PointNet就是这样一种g函数。使用multi-layer perceptron (MLP) 和 max pooling 来建模g函数。
3,相邻点的交互信息必须考虑进去(通过共享的MLP或者2D卷积解决):解决相邻点之间的关联信息问题?
4,网络结构中的T-net作用
论文中指的是将输入点和特征进行对齐、适用于刚性or仿射变换。
通过微型网络(图2中的T-net)预测仿射变换矩阵(仿射变换前是直线,仿射变换后还是直线,直线比例保持不变。),并将该变换直接应用于输入点的坐标。why?
其中的正则化项? 我们约束特征变换矩阵使其接近正交矩阵?
避免n! 排列

