目录说明
根目录下:
train.py用于点云分类训练
provider.py 用于点云的数据预处理(旋转,抖动等)
evaluate用于评估训练结果。
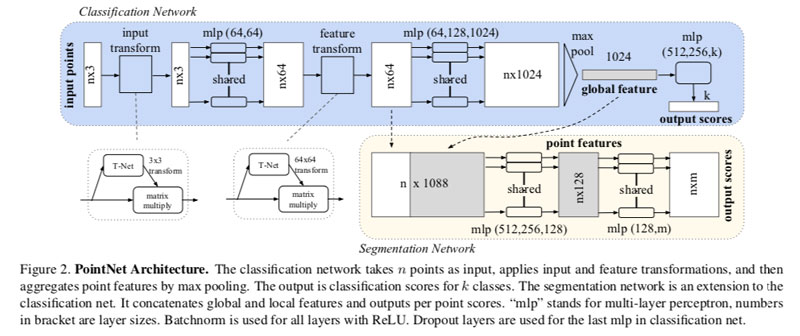
其他目录:data目录下存放用于训练的样例文件h5,test_files与train_files中列举的用于训练及测试的文件路径。log 存放的是训练结果,默认情况下只存放最近一次训练结果。models存放的是模型文件,pointnet_cls.py(POINTNET)和pointnet_cls_basic.py(baseline模型)中的MLP是分类模型结构。pointnet_seg.py是点云分割模型网络;transform_nets.py为原始点云对称变换以及特征变换,即论文中的T-net网络。
1,数据预处理provider
前面下载数据以及后面的hdf5格式加载数据就略过了。说一说数据预处理部分干了些什么。
1,shuffle_data函数
1 | def shuffle_data(data, labels): |
根据labels的长度创建idx下标集合,对下标集合随机打乱,返回打乱的数据data[idx,…] 和labels[idx]。
2,随机旋转点云rotate_point_cloud(参数batch_data)
1 | def rotate_point_cloud(batch_data): |
遍历这批点云物体batch_data.shape[0] 即B的大小。
旋转角度是随机生成的,乘以2$\pi$ ,即使角度多大都没关系,反正按角度算。
计算cos和sin值。
注意此处的旋转矩阵。原一个点云物体k的大小的n*3与旋转矩阵做点积。其实就是物体逆时针旋转那么多角度。对这一批点云物体都做这一个随机旋转角度值。
rotate_point_cloud_by_angle旋转也是同理,不过是指定角度旋转。角度作为参赛输入函数。
3,jitter_point_cloud随机抖动点云
1 | def jitter_point_cloud(batch_data, sigma=0.01, clip=0.05): |
sigma = 0.01, clip = 0.05
sigma sigma np.random.randn(B, N, C) 是均值为sigma的正态分布数据,大小是$B\times N \times C$
将这些数值切割到-0.05到0.05之间,并与原始点云的坐标数据相加。
相当于给点云数据加微小的噪声,增强数据有助于模型的泛化性。
2,基础模型baseline
pointnet_cla_basic.py 函数。就是不看T-net的网络部分。
placeholder_inputs() 根据点云物体一批大小,以及每个点云物体的点的数目声明变量占位。
get_model() 输入大小BxNx3, 输出Bx40 (这个是40个类别分类向量
其中input_image的shape是$B \times N \times 3 \times 1$ , 而输出大小是$B \times 40$ 因为物体是40个类别。
然后就是点云的卷积网络多层感知层MLP,卷积层的卷积核个数为64,大小是$1 \times 3$ ,步长是 $1 \times 1$,padding = valid 不补0,激活函数是Relu。 这几个参数,其中卷积核个数为64表示卷积中输出滤波器filter的数量,$1 \times 3$ 的卷积核大小是因为坐标为xyz。卷积核就会在训练过程中逐步得到一些与点云物体的特殊的特征点。
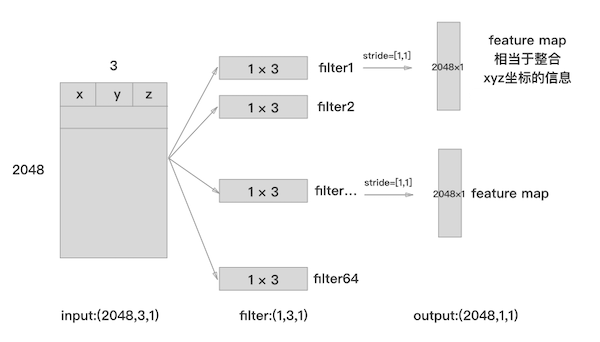
同理,后续的卷积核大小都是(1,1),步长也是(1,1) 都是为了挑选这些特征点(信息点,有趣点),即局部感知,可以想这个网络只是把每个点连接起来而已。
然后经过5个卷积层之后,采用了最大池化。
1 | MaxPooling2D(pool_size=(NUM_POINT,1),strides=[2,2],padding='valid') |
最大池化采用大小为(2,2) 将特征地图缩小一半,并提取关键信息点。同时这里的最大池化将特征点起了对称作用,最后将全局的特征进行聚合。
g是一个对称函数,即maxpool;h是卷积网络;下图中的$\gamma$ 是拟合分类函数(即全连接层逼近复杂函数)。
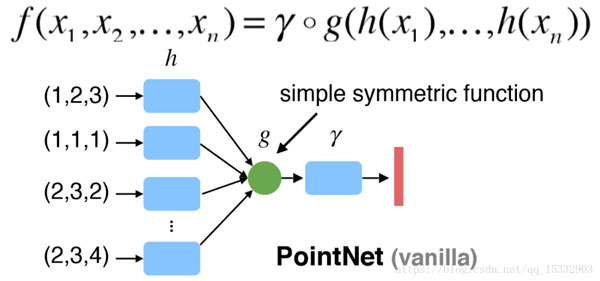
最后的三个全连接网络,大小分别是512,256,40。最后的40输出类别。激活函数为softmax输出概率,哪个概率大则输出就是哪个类别的物体。全连接网络好理解,就是对特征点汇总为全局描述符,最后用于分类。
3,POINTNET网络
T-Net的作用:我们期望通过网络学习到的表征(特征)对于这些仿射变换是不变的。
3.1 Input Transform网络
3.1.1 论文原理
我们通过微型网络(图2中的T-net)预测仿射变换矩阵,将该变换直接应用于输入点的坐标。
3.1.2 源码
1 | transform = input_transform_net(point_cloud, is_training, bn_decay, K=3) |
这个T-net网络也是一个类似前面的baseline模型。这里point_cloud的输入大小是(B = 32, N = 2048, 3) 。然后分别由三个卷积层,大小是64(卷积核大小1×3),128(1×1),1024(1×1),一个最大池化层,两个全连接网络组成。
1 | with tf.variable_scope('transform_XYZ') as sc: |
初始化weights是(256, 9) 大小,biases大小是(9,),biases初始化加常量。transform将net网络即卷积网络(大小是 n × 256,n是个点)于权重(大小是 256 × 9)相乘。
input transform是对空间中点云进行调整,直观上理解是旋转出一个更有利于分类或分割的角度,比如把物体转到正面。
3.2 Feature Transform网络
3.2.1 论文原理
可以在点特征(point features)上插入另一个对齐网络,并预测一个特征转换矩阵以对齐来自不同输入点云(point clouds)的特征。由于特征空间中的变换矩阵具有比空间变换矩阵高(much higher)的维数,这大大增加了优化的难度。 因此,我们在softmax训练损失中添加了一个正则化项。
我们约束特征变换矩阵使其接近正交矩阵:
$A$ 是特征对齐矩阵(由a mini-network T-net预测的),正交变换将不会丢失输入中的信息,因此是需要的。 我们发现通过添加正则项,优化变得更加稳定,并且我们的模型获得了更好的性能。
正交变换是线性变换的一种,它从实内积空间V映射到V自身,且保证变换前后内积不变。对一个由空间投射到同一空间的线性转换,如果转换后的向量长度与转换前的长度相同,则为正交变换。这里正交变换矩阵其实就是用于点云做仿射变换的。
3.1.3 源码
1,网络部分
第二次feature transform是对提取出的64维特征进行对齐,即在特征层面对点云进行变换。
2,损失函数部分
1 | def get_loss(pred, label, end_points, reg_weight=0.001): |
损失函数部分由两部分构成,一部分是交叉熵损失,一部分就是正则化项。
这里Transform的大小是(32,64,64)就是特征转换矩阵,把它与它的转置矩阵相乘$AA^T$。然后与对角矩阵相减 $AA^T - I$ 使这个损失变小。
Reference
1, 开源代码 https://github.com/charlesq34/pointnet
2,1*1 的卷积核 https://zhuanlan.zhihu.com/p/40050371
3,卷积神经网络 https://zhuanlan.zhihu.com/p/47184529
4,点云POINTNET解读 https://blog.csdn.net/tumi678/article/details/80499998
5,损失函数 https://blog.csdn.net/mao_xiao_feng/article/details/53382790

