1 方案学习
1.1 赛题简介
题目:腾讯效果广告采用的是GSP(Generalized Second-Price)竞价机制,广告的实际曝光取决于广告的流量覆盖大小和在竞争广告中的相对竞争力水平。
其中广告的流量覆盖取决于广告的人群定向(匹配对应特征的用户数量)、广告素材尺寸(匹配的广告位)以及投放时段、预算等设置项。而影响广告竞争力的主要有出价、广告质量等因素(如pctr/pcvr等), 以及对用户体验的控制策略。
通常来说, 基本竞争力可以用ecpm = 1000 cpc_bid pctr = 1000 cpa_bid pctr * pcvr (cpc, cpa分别代表按点击付费模式和按转化付费模式)。综上,前者决定广告能参与竞争的次数以及竞争对象,后者决定在每次竞争中的胜出概率。二者最终决定广告每天的曝光量。
本次竞赛将提供历史n天的曝光广告的数据(特定流量上采样), 包括对应每次曝光的流量特征(用户属性和广告位等时空信息)以及曝光广告的设置和竞争力分数;测试集是新的一批广告设置(有完全新的广告id, 也有老的广告id修改了设置)。
目标:预估测试集里这批广告的日曝光量。
1.2 数据分析与清洗
查看数据与预处理:
数据集大小,数据类型,数据是否干净,标签类型,去重,离群点(散点图,删除),缺失情况(背后的意义,业务含义考虑填充),错误值(删除样本,均值或中位数替换等,标签里的错误值 剔除or 标签log化),各类别分布(均值情况,方差情况),大概可以构造的特征,特征之间是否冗余,时间信息。
构造数据
将广告操作表中出价、定向人群、投放时段信息与广告静态表merge。
对日志数据中的广告id构造日曝光量得到新的数据集。
将data与广告静态表进行merge,并给缺失的投放时段填充-999
训练原始特征:
这些特征比较稳定:广告id,素材大小,广告行业id,商品类型,商品id,广告账户id;
广告账户id,出价 定点人群投放时间。
测试集也包含这些特征,然后构造好的广告id和标签数据与广告静态数据经行合并。
1.3 特征工程
类别特征
先处理可以转为自然编码,onehot编码
1,计数count统计(热度啥的,注意特殊值;计数排序 异常值不敏感;label占比的比例(过拟合问题,交叉验证处理);
2,目标编码:出价的均值,点击率均值,或ecpm均值构造(新的广告ID的话,中位数填充)
3,交叉组合(类别与类别组合,粒度更细;类别和数值特征组合,这个类别出价的均价,平均点击率之类的)),可以nunique统计。
4,时序特征:前一两天的曝光值,出价情况等。时间序列考虑历史平均(d-1天的信息作为d天的特征)。
存在一个不存在的类别,缺失值的话用中位数或均值填充。
5,数值特征可以均值统计,最大最小,中位数等。
6,其他注意
细粒度的特征增强模型的刻画能力,粗粒度的特征保证模型的泛化能力。细粒度的特征对活跃用户比较好,可以更精细地刻画他的喜好,提供更个性化的商品排序;而粗粒度的特征是为了服务不活跃用户甚至是新用户,用大数据中总结出的一般规律来提供商品的排序。
为了避免过拟合,注意(5折)交叉统计构造特征。
CountVectorizer是属于常见的特征数值计算类,是一个文本特征提取方法。对于每一个训练文本,它只考虑每种词汇在该训练文本中出现的频率。对于多值特征,最方便的展开方式就是使用CountVectorizer。
数值特征
1,分桶:转为离散特征,就可以交叉组合。数值特征可以均值统计,最大最小,中位数等。
2,特征交叉:加减乘除等。根据业务出价 × 点击率 = ecpm 值。还可以类别与数值交叉。
时间特征
1,日期变量:年、月、周、日、小时、分钟等
2,时序相关特征:历史平均,历史曝光率,历史PCTR,滑动窗统计。d-1天的信息作为d天的特征,这种相近日期的数据相关性是非常大的。
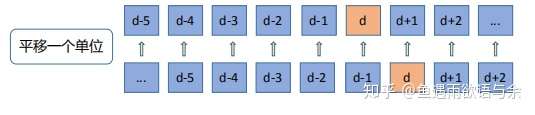
特征筛选
1,过滤法:卡方检验 衡量x、y的相关性,相关系数来衡量特征间的相关性
2,封装法:逐个添加特征来判断效果好不好(前向,后向搜索),变好就选它,不适合特征太多的情况
3,嵌入法:基于学习模型的特征排序。如 树模型LightGBM可以返回特征的重要性,反映特征在训练过程中的分裂次数(越多,重要性越高),信息增益情况,按高低排序,阈值排序。
一些trick
1,模型与规则:比如历史平均来填充旧广告id的曝光量,新广告id曝光量用广告size、商品id等特征对应历史平均来填充。调整单调性。
2,目标编码防过拟合:进行目标编码的时候没有防过拟合处理,导致数据泄露。有效的办法是采用交叉验证的方式,比如我们将将样本划分为5份,对于其中每一份数据,我们都用另外4份数据来构造。

1.4 模型训练与验证
Baseline:XGboost或LIghtGBM,对特征处理要求低,对类别和连续特征友好,缺失值不需要填充。
交叉验证:时序问题,为了避免数据泄露,常选择训练集最后一天进行线下验证,或者K-folds交叉验证。
模型融合:特征差异,样本差异(交叉验证中选择的样本是不一样的),模型差异(树模型,深度模型等)
训练过程融合:Bagging与Boosting
训练结果融合:投票法(类别),平均法(回归),Stacking
要不断尝试新idea,向优秀选手提问,赛后总结看优秀方案。
2 源码阅读
数据处理
1 | pd.read_csv().sort_values() // 排序 |
Reference
1,https://algo.qq.com/application/home/rankinglist/rankingList.html 腾讯算法大赛
2,https://zhuanlan.zhihu.com/p/63718151 鱼佬知乎 https://zhuanlan.zhihu.com/p/73062485

