// C++ template <typename E, typename Comp> voidinssort(E A[], int n){ for (int i=1;i<n;i++) for (int j=i; (j>0)&&(Comp::prior(A[j],A[j-1])); j--) swap(A, j, j-1); }
1 2 3 4 5 6
# python definsert_sort(array): for i in range(0,len(array)): for j in range(i,0,-1): if j>0and array[j] < array[j-1]: array[j],array[j-1] = array[j-1],array[j] # change the elem
# python defbubble_sort(array): for i in range(0,len(array)-1): flag = 0# trace the exchange times for j in range(len(array)-1,i,-1): if array[j] < array[j-1]: array[j], array[j - 1] = array[j - 1], array[j] flag = 1 if(flag==0): return
内层的for循环比较次数总会是 i,因此最差时间代价是:$\sum_{i=1}^n i \approx n^2/2 = \Theta(n^2)$ ,平均也是类似插入排序$\Theta(n^2)$,它是稳定的排序。
defselect_sort(array): for i in range(0,len(array)-1): lowindex = i for j in range(len(array)-1, i, -1): if array[j] < array[lowindex]: lowindex = j array[i], array[lowindex] = array[lowindex], array[i]
//shellsort template <typename E> voidinsort(E A[],int n, int increment){ for (int i=increment; i<n; i+=increment) { for (int j=i; (j>=increment)&&(A[j]<A[j-increment]); j-=increment) { E temp = A[j]; A[j] = A[j-increment]; A[j-increment] = temp; } } }
template <typename E> voidshellsort(E A[],int n){ for (int i=n/2; i>2; i/=2) { for (int j=0; j<i; j++) { insort<E>(&A[j], n-j, i);//A[j] is the start address 偏移,巧妙 } } insort<E>(A, n, 1); }
intmain(){ int num[16] = {59,20,17,13,28,14,23,83,36,98,11,70,65,41,42,15}; shellsort<int>(num, 16); for (auto n:num) { cout<<n<<endl; } return0; }
Python:
1 2 3 4 5 6 7 8 9 10 11 12
def shell_sort(array): n = len(array) gap = n // 2 while gap > 0: for i in range(gap,n): temp = array[i] j = i while j >= gap andarray[j-gap] > temp: array[j] = array[j-gap] j-=gap array[j] = temp gap //= 2
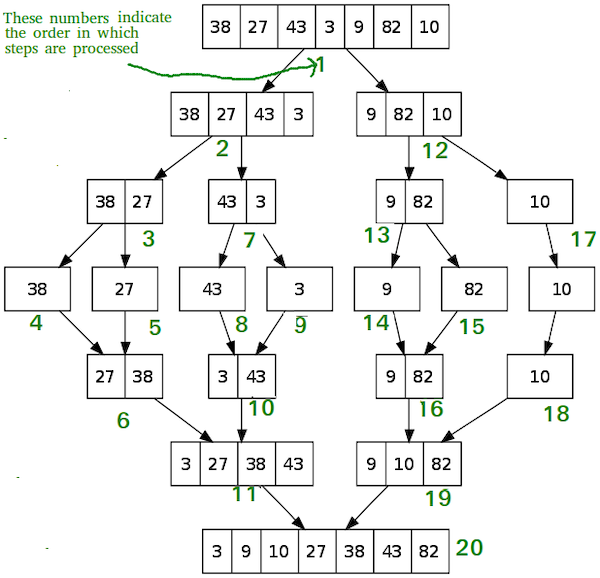
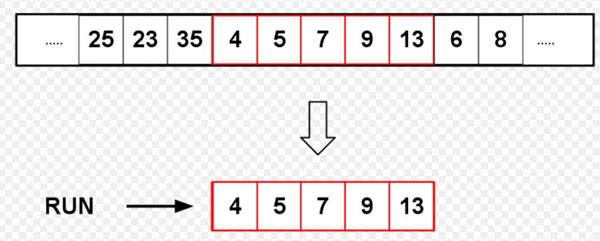
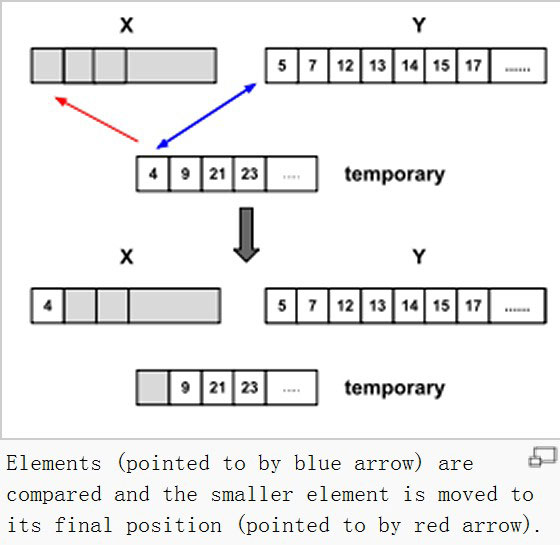
mergesort
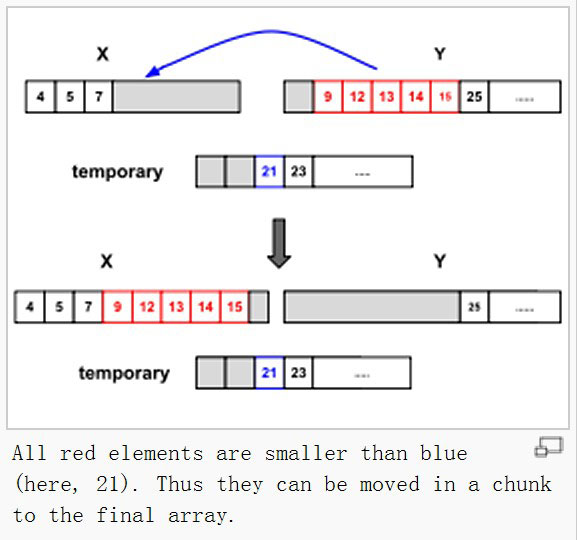
来源于分治的思想,在排序问题上分治的思想体现在把待排序的列表分成片段,先处理片段,然后将片段重组。
伪代码的提现其思想:
1 2 3 4 5 6
List mergesort(List inlist){ if(inlist.length() <= 1) return inlist; List L1 = half of the list; List L2 = other half of the list; return mergesort(mergesort(L1),mergesort(L2)); }
voidswap(int A[], int i, int j) { int temp = A[i]; A[i] = A[j]; A[j] = temp; }
intpartition(int A[],int l, int r, int& pivot){ do{ while(A[++l] > pivot); //move the index while((l<r) && (A[--r] < pivot)); swap(A,l,r); }while(l<r); return l; }
voidmyqsort(int A[],int i,int j){ if (i >= j) return; int pivotIndex = (i+j)/2; //这里可以写一个findpivot函数,三者取中(三个随机值的中间) swap(A,pivotIndex,j); int k = partition(A,i-1,j,A[j]); //k is the start of the left half swap(A,k,j);// 轴值就在k位置,就是最终排序好的数组中的位置 myqsort(A,i,k-1); myqsort(A,k+1,j); }
defquick_sort(array, left, right): if left >= right: return low = left high = right key = array[low] while left < right: while left < right and array[right] > key: right -= 1 array[left] = array[right] while left < right and array[left] <= key: left += 1 array[right] = array[left] array[right] = key
quick_sort(array, low, left - 1) quick_sort(array, left + 1, high)
# To heapify subtree rooted at index i , n is size of heap defheapify(array,n,i): largest = i # init largest as root l = 2 * i + 1 r = 2 * i + 2 # See if left child of root exists and is greater than root if l < n and array[i] < array[l]: largest = l # See if right child of root exists and is greater than root if r < n and array[largest] < array[r]: largest = r
# Change root, if needed if largest != i: array[i], array[largest] = array[largest], array[i] # swap # Heapify the root heapify(array, n, largest)
# The main function to sort an array of given size defheapSort(arr): n = len(arr) # Build a maxheap. for i in range(n, -1, -1): heapify(arr, n, i) # One by one extract elements for i in range(n - 1, 0, -1): arr[i], arr[0] = arr[0], arr[i] # swap heapify(arr, i, 0)
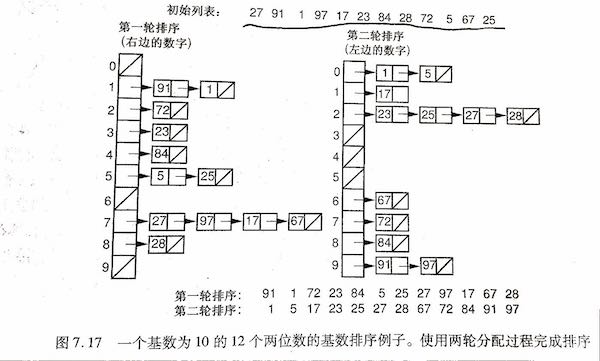
//每一轮分配结束时,记录都被复制回原数组 voidradix(int* A, int* Bin,int n,int k,int r,int cnt[]){ //n is the size of A //k is the digit of A[max], r is Cardinality 10 (make r from 1 to 10 to 100) //cnt[i] stores occurrences of records in bin[i] int j; for (int i=0,rtoi=1; i<k; i++,rtoi*=r) { for (j=0; j<r; j++) cnt[j] = 0; //init cnt,roti save the r^i //count the number of records for each bin on this pass for (j=0; j<n; j++) cnt[(A[j] / rtoi) % r]++; //index of B: cnt[j] will be index for last slot of bin j for (j=1; j<r; j++) cnt[j] = cnt[j-1] + cnt[j]; //put records into bins, work from bottom of each bin //since bins fill from bottom, j counts downwards for (j=n-1; j>=0; j--) { Bin[--cnt[ (A[j] / rtoi) % r] ] = A[j]; } //copy B back to A for (j=0; j<n; j++) { A[j] = Bin[j]; } cout<<endl; } }
intmain(){ //n is the size of A,k is the digit of A[max], r is Cardinality 10 (make r from 1 to 10 to 100) int n = 12; int k = 2; int r = 10; int A[12] = {27,91,1,97,17,23,84,28,72,5,67,25}; int B[12] = {0,0,0,0,0,0,0,0,0,0,0,0}; int cnt[10] = {0}; radix(A,B,n,k,r,cnt); for (int i=0; i<n; i++) { cout<<A[i]<<" "; } return0; }