ABS & Intro
云系统背景
许多组件,复杂交互:cloud-based and cloud-centric systems always consist of a mass of components running in large distributed environments with complicated interactions.
性能问题
引起性能问题的一些因素:highly dynamic runtime environment changes (e.g., overload and resource contention竞争,内部损伤) or software bugs (e.g., memory leak 外部)
必要性:在多租户云平台中,由于多个应用程序在同一位置,资源争用会导致持久的性能下降。在实际的生产系统中,性能问题可能会导致巨大的收入损失。(亚马逊数据)
定位好处:为系统管理员提供一些见解,例如瓶颈在哪里,或者两个应用程序适合共存于同一台机器上。如果快速找到根本原因,则可以显着降低云应用程序的MTTR。
细粒度根因定位困难
困难原因:due to complicated interactions and a large cardinality of potential cause set.
系统监控
监控中心以固定的时间间隔收集性能指标(例如CPU使用率),并在SLO(Service level objective)指标(例如响应时间)超过预设阈值时发出警报。 如果发生警报,系统管理员将始终手动查明罪魁祸首。 但手动诊断可能非常费力费时容易出错。
本文内容
构建CauseInfer系统,指出根因原因与给出提示。
CauseInfer可以自动将分布式系统映射到两层分层的因果关系图,并沿着因果关系图中的因果路径推断根本原因。 CauseInfer以明确的方式对故障传播路径进行建模,并且无需对正在运行的生产系统进行检测即可工作,
这使得CauseInfer比以前的方法更加有效和实用。 在两个基准系统中的实验评估表明,CauseInfer可以高精度地识别根本原因。 与几种最新方法相比,CauseInfer可以实现10%以上的改进。 此外,CauseInfer轻巧且足够灵活,可以轻松地在大型分布式系统中进行扩展。 使用CauseInfer,可以显着减少云系统的平均恢复时间(MTTR)。
文献综述
一些不足
粗粒度
一些工作着重于粗略地定位故障(例如,服务级别[5],[6]或节点级别[7],[8],[9]),而不是细粒度地确定真正原因粒度(例如,代码段[10],[11],[12]或配置项)。我们认为,粗粒度的故障定位还远远不够,因为它无法为我们提供更多根本原因的详细信息,这使得及时恢复系统变得困难。
相当大的开销
为了缩小故障位置,几个系统[10],[12],[13],[14]可以非常精细地确定根本原因。但是他们需要检测应用程序源代码或正在运行的系统,这给生产系统带来了可观的开销。
因果关系弱
大量工作[6],[7],[8],[15]以成对方式利用“相关性correlation”分析来发现服务依赖性或运行时系统度量间的依赖性,并推断出根据这些依赖关系的根本原因。但是,“相关”并不等同于“因果关系”。弱的因果关系可能导致诊断结果不准确。
OurWork
目标
在开销和粒度之间存在冲突时,要在两者之间取得平衡是一项艰巨的工作。细粒度总是意味着高开销。本文提出了一种解决方案,可以在不考虑开销的情况下进行细粒度的诊断。
性能问题原因大致分为两类:即外部和内部损害。前一类包括资源争用,配置错误,过载,资源消耗等等。后者主要指软件错误。此外,我们的主要观察结果是,大多数此类损害可以通过运行时系统指标直接或间接地表现出来,这将在第2节中更详细地说明。此外,这些指标可以通过现成的工具轻松监控。根据此观察,我们的目标是通过将原因归因于最相关的运行时系统指标来缩小导致性能问题的可能原因。例如,如果系统中发生并发错误,则根本原因应归因于违反的“锁定”指标。
两关键问题
i)如何对正在运行的服务和运行时性能指标之间的因果关系进行建模,以及(ii)如何使用具有成本效益的方法来推断根本原因。
CauseInfer简介
根因指标的变化会导致effect metric的改变,CauseInfer的本质是建立因果图,该因果图用于为运行分布式系统的故障传播路径建模并在因果图中沿因果路径推断根本原因。 为此,CauseInfer首先从多个数据源收集运行时性能指标,然后通过贝叶斯变化点检测方法 提取嵌入在这些指标中的变化点。
利用变化数据,CauseInfer通过基于统计的方法构造两层层次因果图,以解决关键问题(i)。该因果图由一个粗粒度图和一个细粒度图组成。前一个图是通过一种新颖的轻量级流量滞后相关方法(traffic lag correlation method)构造的服务级依赖图,旨在将根本原因定位在服务级别上。而后一个图是系统指标/度量metric因果关系图(system metric causality graph),它是通过条件独立性测试[16]在运行时性能指标中构建的,目的是在指标级别找到真正的罪魁祸首。
为了解决关键问题(ii),针对每个节点1专门构建指标因果图。应用程序的SLO(Service level objective)指标将来自不同节点的两个指标因果关系图链接在一起。
CauseInfer部署在基于云的系统中。它着重于诊断导致虚拟服务器中违反SLO的性能问题。 CauseInfer通过监视服务的响应时间来检测SLO违规。其他SLO指标(例如,可用性)将在我们的未来工作中进行讨论。(不会影响SLO的性能问题不在本文讨论范围之内。例如,除非服务器的内存使用率很高,否则CauseInfer将不会开始诊断,除非请求响应时间很高。)此外,系统崩溃也不在我们的考虑范围之内,因为可以通过诸如Sherlock [17]之类的传统工具来解决它们。
一旦发生SLO违规,就会触发推理过程。 CauseInfer首先通过分析特定服务的SLO指标来定位故障。然后,它通过检测因果路径上有故障的节点中的性能指标违规来查明根本原因。重复该过程,直到揭示出所有潜在的根本原因。由于采用了分层图结构,在推理过程中跳过了一些常规路径,因此大大缩短了推理时间。在两个测试基准中的实验评估,即在线事务处理(OLTP)基准:TPC-W [18]和大数据基准:BigDataBench [19],表明CauseInfer可以准确地找出根本原因,并且胜过几种最先进的方法。
贡献
1,Bayesian change point 检测方法
2,通过分析两个服务之间的通信延迟相关性the traffic lag correlation,提出了一种新颖的轻量级服务依赖发现方法。 服务依赖关系图非常有效地指导我们在服务级别上定位性能问题。
3,我们设计了一种新颖的方法来发现从多个数据源收集的运行时系统指标之间的因果关系。 与基于correlation-based approaches 相关的方法不同,该方法利用条件独立性测试来精确快速地对系统故障之间的故障传播路径进行建模。
4,CauseInfer系统
故障背景与动机
云平台需要诊断工具
举例:在Hadoop错误库有一个真正的性能错误,即Hadoop-3382。 未完全关闭打开的文件时,在namenode中发生内存泄漏。 而且内存泄漏将延长Hadoop请求的响应时间。 故障传播路径是“打开的文件→内存利用率→响应时间”。 如果事先知道故障传播路径,则可以查明性能问题的根本原因。 以Hadoop-3382为例,一旦作业执行时间变得异常,我们就可以在“打开的文件”中找到根本原因。 这促使我们对故障传播路径进行显式建模。
性能问题分类
引用【7,8,15】,我们发现性能问题可能是由运行时环境更改或软件错误引起的。通过手动分析这些原因,这些原因与 物理资源(例如,CPU和内存)或逻辑资源(例如,锁和队列)高度相关,并且可以很容易地监视这两个原因。这一发现也与[11]中的观察结果相符,在该发现中作者声称可以通过 分析系统调用(例如sys write,sys open,sys futex等)来诊断性能错误。这些系统调用用于为应用程序提供接口,以利用物理或逻辑系统资源。
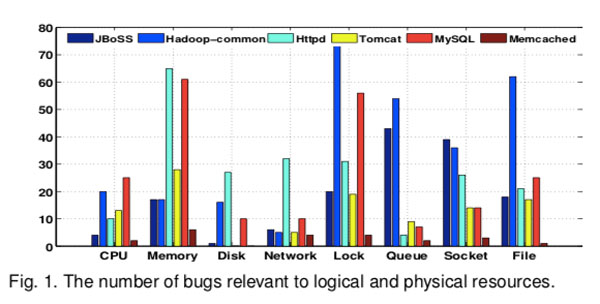
如图1所示。因此,通过分析物理或逻辑资源利用率,我们可以细粒度地诊断性能问题。
相关性陷进
大量现有文献利用“相关性”(例如,皮尔逊相关系数)对服务[5],[6]或系统指标[2],[7],[8]之间的依赖关系进行建模。我们认为基于“相关性”的方法可能会错误地将某些独立关系视为依赖关系的可能性很高。原因是该方法旨在仅捕获两个指标之间的简单关联。它不能捕获两个以上指标之间的更复杂的依赖关系,称为“条件依赖”。
(CauseInfer论文(Part Ⅱ) CauseInfer的工作流模型)
Reference
1, Chen P, Qi Y, Hou D. CauseInfer: automated end-to-end performance diagnosis with hierarchical causality graph in cloud environment[J]. IEEE transactions on services computing, 2016, 12(2): 214-230.

