Background
优化原理
参考JS的V8里头的优化说明:
With the x86-64 instruction set, this means we can’t use direct calls: they take a 32-bit signed immediate that’s used as an offset to the address of the call, and the target may be more than 2 GiB away. Instead, we need to rely on indirect calls through a register or memory operand. Such calls rely more heavily on prediction since it’s not immediately apparent from the call instruction itself what the target of the call is.
It should reduce strain on the indirect branch predictor as the target is known after the instruction is decoded, but it also doesn’t require the target to be loaded into a register from a constant or memory.
并且前文我们在看JIT Buffer relocation的性能分析(https://saruagithub.github.io/2022/06/13/20220713mmap代码段JIT buffer重定位/)的时候就已经发现了减少indirect call是可以大大提高预测准确率的,因此我们进一步来分析当前JIT里头的indirect call
问题调研
get indirect and direct branch statistics before and after JIT buffer relocation patch to see whether indirect branch still exists
我们看JITted code生成的模板里的indirect call还有多少,ext/opcache/jit/zend_jit_x86.dasc 原始实现
1 |
|
这个模板文件里如果从当前位置call func,跳转距离在IS_32BIT的话,就是direct call 。否则就生成indirect call,通过寄存器来访问地址。这样就得需要分支预测器BPU进行预测了。
1 | # this JITTed stub func call func by indirect call |
所以我们尝试去掉用寄存器访问地址。
代码实现
1 | // easy implement |
Indirect call reduction for Jit code by wxue1 · Pull Request #9579 · php/php-src
这里需要注意特殊的情况,距离是前后2GB以及一些特殊case。
1 |
|
1 | --- I change the EXT_CALL code and use direct call --- |
对runtime生成的JITTed code去验证字节码:
1 | 0x0000555596e00610 <+0>: 66 c7 02 13 7f mov WORD PTR [rdx],0x7f13 |
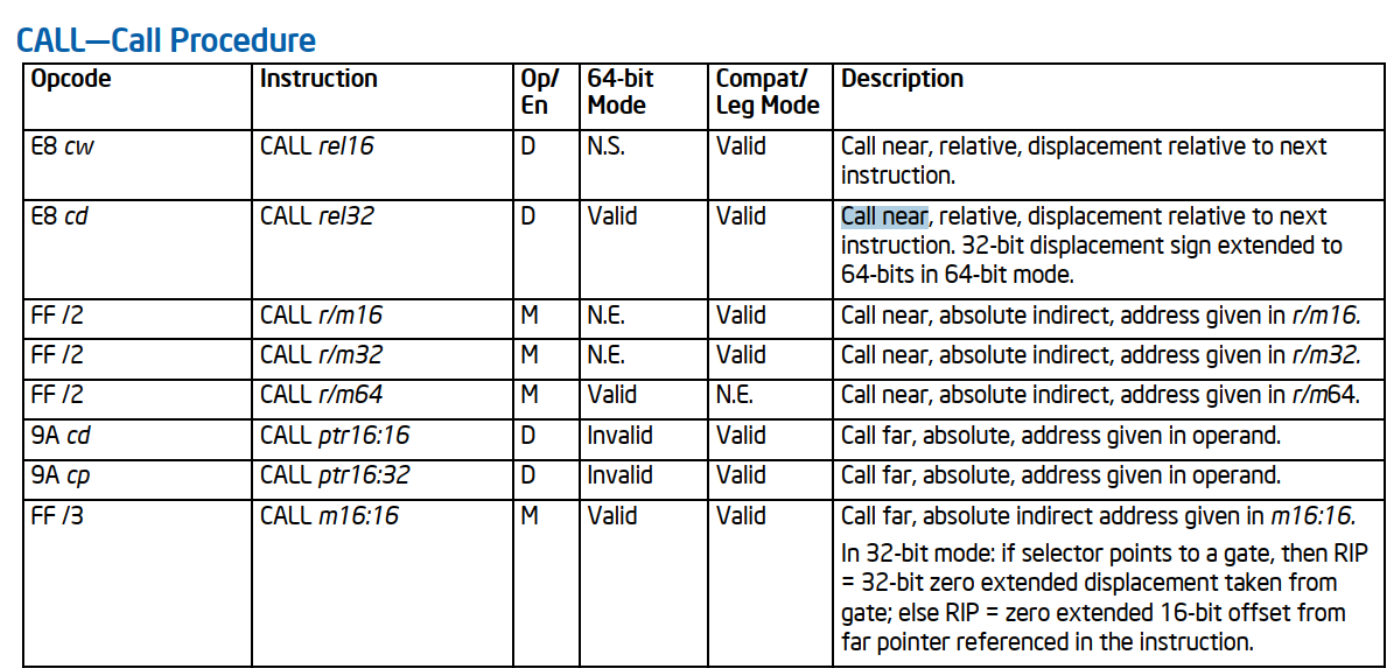
我们去看intel的SDM手册,可以看到第二行 E8这个操作码可以call rel32 (rel指的是relocation, 是an offset to the address of the call),这是相对近调用,相对于下一指令的位移
Emon性能分析
我们再对优化后的workload压测跑分,收集emon数据进行分析,看看具体的优化效果如何。
这里的数据我是从JIT buffer relocation,到64bit packing 到 direct call 每个优化一步步收集起来的。我们直接看最后的direct call的分析。数据是wordpress,SPR D0 56core上跑的
- TPS 整体提高了1%
- code cache miss整体变好了,但其实是因为分支预测更好了,加载指令更快也更准确了。
- 最根本的优化是对Branch prediction的,表现类似于relocation优化。总的分支执行更快了,误预测的更少
- 具体去分析branch类型和误预测的类型,也可以看出来整体的Direct call更多,Indirect call更少
- 从误预测的情况来看,indirect call预测失败也下降了很多,几乎75%
- 并且indirect call的预测已经比较准了,误预测率占2.2%,很少了。反而看起来现在是条件分支的差一些 8.7%算比较高的误预测率了。
- 可以估计下一次indirect call会多消耗多少cycle数
in excel, =(P9/P76) 就是计算的这个,可以看到大概每transaction,一次indirect call func大概会消耗44.9 cycles。这个计算在relocation patch那里的emon数据和direct call的数据是基本一致的。
Summary
通用优化思路
indirect call转为direct call是非常常见的优化。
遗留问题
- dynasm 生成字节码的原理
- 还有其他地方的indirect call么
- 条件分支的预测优化??

