数组实现堆 发表于 2020-03-28 更新于 2022-07-13 分类于 算法 Valine: 完全二叉树完全二叉树,逐层而下,从左到右,结点的位置完全由其序号觉得,因此可以用数组来实现。计算各结点下标的公式,其中$r$ 表示结点的下标,范围在0 ~ n-1 之间,n是二叉树结点的总数。$Parent(r)= \lfloor (r-1)/2 \rfloor$ 向下取整,当$r≠0$时$Leftchild(r)=2r+1$,当$2r+1<n$时 阅读全文 »
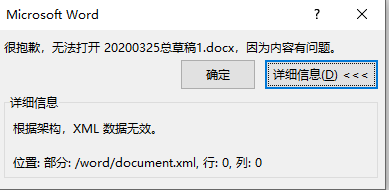
20200325word的xml无效而无法打开 发表于 2020-03-26 更新于 2022-07-13 分类于 配置 Valine: 问题写论文生成word的时候出现了xml无效的问题。将word文档原扩展名“docx”手动改为压缩文件扩展名“zip”,备份一个,然后用解压软件解压。用vscode编辑器或者其他的一些xml编辑器(如firstobject)打开解压文件夹下的word目录下的document.xml 文件。根据对xml错误提示进行更改。 阅读全文 »
Unsupervised Anomaly Detection via Variational Auto-Encoder for Seasonal KPIs in Web Applications (Donut model, Part Ⅱ) 发表于 2020-03-14 更新于 2022-07-13 分类于 AIOps Valine: Evaluation实验Datasets我们从大型互联网上获得了18个维护良好的商业KPIs(时间跨度足以进行培训和评估),所有的KPIs间隔为1min。三个数据集 A B C 如图6的Table1。因此我们可以评估Donut在不同级别的噪声。 我们将每个数据集分为训练集 49%,验证集21%和测试集30%。 阅读全文 »
Unsupervised Anomaly Detection via Variational Auto-Encoder for Seasonal KPIs in Web Applications (Donut model, Part I) 发表于 2020-03-13 更新于 2022-07-13 分类于 AIOps Valine: ABS&IntroAbstract大的互联网公司一般会密切监控KPIs。然而这些有不同模式不同数据质量的季节性KPIs的异常检测很有挑战,特别是无标签。本文中,我们提出了Donut,基于VAE(Variational Auto-Encoder 变分自动编码器)的无监督异常检测算法,其最佳F-score达到0.75 ~ 0.9。我们为Donut的重构提出了一种新颖的KDE解释,使其成为第一种基于VAE的异常检测算法,并且具有扎实的理论解释。 阅读全文 »
Computers&Operations Research部分论文简读 发表于 2020-03-10 更新于 2022-07-13 分类于 AIOps Valine: Exact and heuristic approaches to detect failures in failed k-out-of-n systemsABS&Intro背景本文考虑n个系统中k个故障了(表决系统),相应的测试每个组件是有成本的。另外,我们具有某些组件是故障的原因的先验概率信息。目标是以最小的预期成本去识别导致故障的那部分组件。 阅读全文 »
排序算法复习 发表于 2020-03-10 更新于 2022-07-13 分类于 算法 Valine: 排序算法排序算法在搜索中常用,因此非常重要。排序算法里包含了重要的分治的思想,就是在划分子问题上。归并排序将数据折半划分,快速排序将数据分成大数和小数部分,基数排序则每次都会按照关键码中的一个数字划分数据。什么是稳定的排序:如果一种排序算法不会改变关键码值相同的记录的相对顺序,则称为稳定的。三种基本的排序算法 阅读全文 »
DFS与BFS算法 发表于 2020-02-28 更新于 2022-07-13 分类于 算法 Valine: 1 简介深度优先搜索从某个状态开始,不断的转移状态直到无法转移,然后回退到前一步的状态。执行的过程其实是跟栈有关,因为暂时没有执行的部分会被存放到堆栈里。直白点就是一条道走到黑,然后再逐步掉头,继续走到头。一般要注意算法停止条件。迭代过程分析。2 DFS类题目部分和问题给定整数$a_{1}, a_{2}, \cdots, a_{n}$ ,判断能否可以从中选出若干数,使他们的和恰好为$k$ 阅读全文 »
字节算法岗面试记录 发表于 2020-02-10 更新于 2022-07-13 分类于 经历 Valine: 一面面试官真的是很直接了,就出了道算法题。但整体来说这个面试官真的是超级好了啊,特别会引导,我觉得字节就是这点细节很好。最大连续序列和。如给一个Array: 1,-2,3,1,-1,5 。则是8 (3, 1, -1 , 5)分析:设DP[k] 是表示以k结尾的最大的和。则递推公式为 DP[k] = max{DP[k-1] + A[k] ,A[k] },要么是前一个连续和加上数组值(当前数组值为正),要么就是数组本身。这样最后只需要一遍遍历过去,找出以某个k结尾的最大和的那个DP值即为答案。 阅读全文 »
异常检测方法 发表于 2020-02-10 更新于 2022-07-13 分类于 AIOps Valine: 异常检测方法综述统计方法有基于阈值的,还有对数据的分布做出假设,并找出假设下所定义的“异常”,因此往往会使用极值分析或者假设检验,概率密度函数值小于某个阈值的点判定为异常。 还有些多元模型,如计算多个事件指标之间期望的相关性等等。看图频率直方图, 点分布图高斯分布的 k-sigma概率密度函数为 $f(x)=\frac{1}{\sqrt{2 \pi} \sigma} e^{-\frac{(x-\mu)^{2}}{2 \sigma^{2}}}$ 阅读全文 »
DP算法 发表于 2020-02-10 更新于 2022-07-13 分类于 算法 Valine: 1 经典的背包问题有n个重量和价值分别为$w_i,v_i$ 的物品,从这些物品中挑选出总重量不超过W的物品。求所有挑选方案中价值总和的最大值。限制条件: 阅读全文 »