基础
虚拟化技术
Hadoop
hadoop是一个开源框架,允许使用简单的编程模型在跨计算机集群的分布式环境中存储和处理大数据。
HDFS
分布式文件系统,是一个高度容错性的系统(每个数据块都复制到多个节点),可以提供高吞吐量的数据访问(T级别,多个节点同时处理数据)。
文件分块存储,HDFS将一个完整的大文件平均分块存储到不同的计算器上,多主机读取比单主机读取效率更高。代码向数据迁移,尽量地将任务分配到离数据最近的机器上运行。
适用情况:大规模数据,流式数据(一次写入多次读写,不支持动态改变文件内容,不支持并发写,小文件不合适。),一般硬件,时间延迟有代价(低时延的访问需求HBase更合适)。
关键元素
Block:文件分块,一般大小是64MB or 128MB。配置大的块减少搜寻时间,减少管理块的数据开销,每个块都需要在NameNode上有对应的记录;对数据块进行读写减少建立网络的连接成本。每个块都会被复制到多台机器(可靠性)。
NameNode:保存整个文件系统的目录信息,文件信息及分块信息。存储文件的metadata,运行时所有数据都保存到内存,整个HDFS可存储的文件数受限于NameNode的内存大小。一个Block在NameNode中对应一条记录
DataNode:分布在廉价的计算机上,用于存储Block块文件。负责数据的读写操作和复制操作,DataNode启动时会向NameNode报告当前存储的数据块信息。DataNode之间会进行通信,复制数据块,虽然有冗余但是可靠。
结构如图:
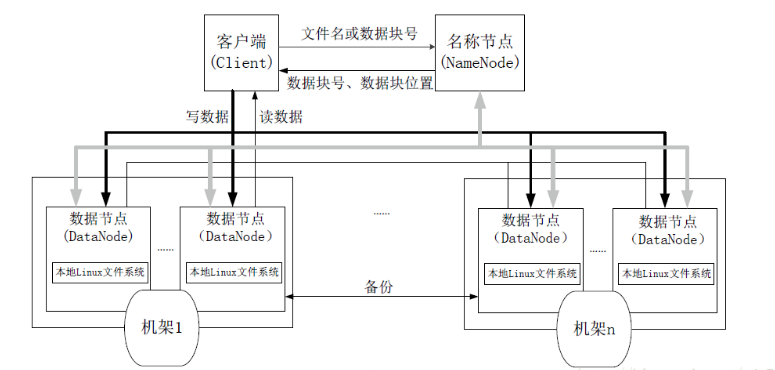
名称节点(NameNode) 主节点(Master),数据节点 (DataNode) 从节点(Slave)
名称节点负责文件和目录的创建、删除和重命名等,同时管理数据节点与文件块的映射关系;数据节点负责数据的存储和读取。
HDFS的数据流—读文件
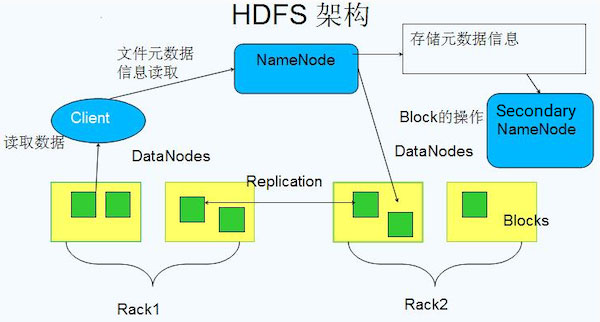
客户端client用FileSystem的open() 函数打开文件。
DistributedFileSystem用RPC调用元数据节点,得到文件的数据块信息。对于每一个数据块,元数据节点返回保存数据块的数据节点的地址。
MapReduce
是一套从海量数据中提取分析元素,最后返回结果集的编程模型。MapReduce的基本原理就是:将大的数据分析分成小块逐个分析,最后再将提取出来的数据汇总分析,最终获得我们想要的内容。
一种分布式的计算方式指定一个Map函数,用来把一组键值对映射成一组新的键值对,指定并发的Reduce(归约)函数,用来保证所有映射的键值对中的每一个共享相同的键组。
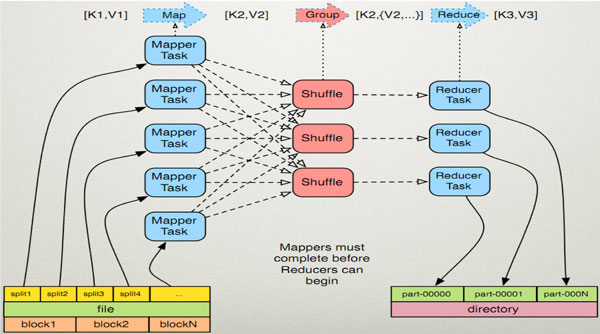
map: (K1, V1) → list(K2, V2) combine: (K2, list(V2)) → list(K2, V2) reduce: (K2, list(V2)) → list(K3, V3)
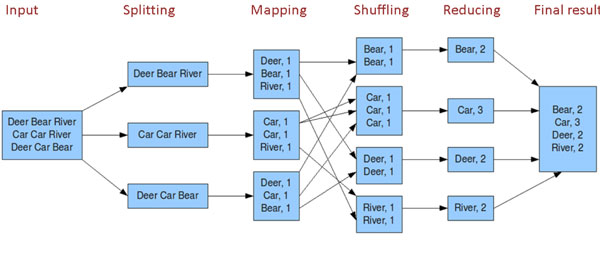
多节点下流程图:
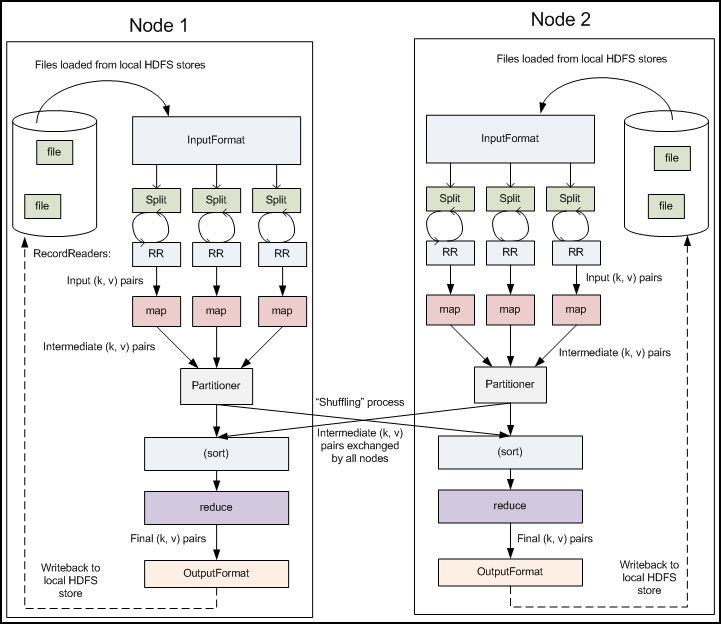
Record reader:记录阅读器会翻译由输入格式生成的记录,记录阅读器用于将数据解析给记录,并不分析记录自身。记录读取器的目的是将数据解析成记录,但不分析记录本身。它将数据以键值对的形式传输给mapper。通常键是位置信息,值是构成记录的数据存储块.
Map:在映射器中用户提供的代码称为中间对。对于键值的具体定义是慎重的,因为定义对于分布式任务的完成具有重要意义.键决定了数据分类的依据,而值决定了处理器中的分析信息。
Shuffle and Sort:ruduce任务以随机和排序步骤开始。此步骤写入输出文件并下载到本地计算机。这些数据采用键进行排序以把等价密钥组合到一起。
Reduce:reducer采用分组数据作为输入。该功能传递键和此键相关值的迭代器。可以采用多种方式来汇总、过滤或者合并数据。当ruduce功能完成,就会发送0个或多个键值对。
输出格式:输出格式会转换最终的键值对并写入文件。默认情况下键和值以tab分割,各记录以换行符分割。因此可以自定义更多输出格式,最终数据会写入HDFS。
Reference
1,《云计算课程》
2,W3Cschool: https://www.w3cschool.cn/hadoop/fgr61jyf.html

