SSH远程
1,在mac上用parallels desktop开启一个Ubuntu16的虚拟机。
注意设置里换源,中国区的快些。
然后进行更新 (sudo apt-get update , 然后sudo apt-get upgrade)
然后安装ssh(sudo apt-get install openssh-server)。
然后我在本机mac这边用ssh远程登录ubuntu。将mac的ssh公钥发送给ubunt,(ssh-copy-id *@10.211.55…IP),以后就可以直接ssh user@IP登录ubuntu了。
下载资源
Java环境
在 Linux 中下载java JDK,下载的Linux X64的1.7版本的jdk-7u80
https://www.oracle.com/java/technologies/javase/javase7-archive-downloads.html#jdk-7u80-oth-JPR
我远程scp传到ubuntu的时候提醒connection refused,这个是因为我mac的setting里的sharing的remote login没有开启,这里得开启一下。
接着配置Java环境变量,配置在/etc/profile中,作为全局系统变量,使用sudo vi /etc/profile进行环境变量编辑,
1 | 添加并保存 |
编辑完后终端输入source /etc/profile使环境变量生效。
hadoop下载
下载的hadoop2.6版本。
1 | wget --no-check-certificate -c --header "Cookie: oraclelicense=accept-securebackup-cookie" http://archive.cloudera.com/cdh5/cdh/5/hadoop-2.6.0-cdh5.7.0.tar.gz |
然后对hadoop进行解压放到与jdk同一个目录中:
1 | tar -zxvf hadoop-2.7.1.tar.gz -C /usr/local |
配置hadoop全局环境变量并使其生效,在Java环境变量配置的下面:
1 | HADOOP VARIABLES |
编辑完后终端输入source /etc/profile使环境变量生效。
另外这里注意配置hadoop-env.sh文件的$JAVA_HOME,接着用sudo gedit hadoop-env.sh配置jdk绝对路径:
1 | export JAVA_HOME=/usr/local/java/jdk1.7.0_80 #注意此处jdk目录与你解压目录相同 |
环境配置
映射配置
使用 vim 进入到 “/etc/hostname” 的这个文件进行修改,我修改了为“wangxue-para”,同时修改“/etc/hosts”文件,在里面追加 IP 地址与 wangxue-para 主机的映射。
配置免秘钥登录
整个hadoop的处理过程之中,都是利用ssh实现通讯的,就算是在本机,也一样使用ssh进行通讯处理,因此需要在电脑上配置ssh免登录处理。
在本主机上生成一个ssh key:使用sudo apt-get openssh-server安装openssh-server后,然后使用ssh-keygen -t rsa -P “”生成.ssh文件
保存公钥:这个时候的程序如果要想进行登录依然需要密码。需要将公钥信息保存在授权认证的文件之中 : “authorized_key”文件里面。cd .ssh/进入到该文件中,然后使用 ls 命令查看其中的文件,然后使用cat id_rsa.pub >> authorized_keys把公钥存到authorized_keys文件中,最后使用ssh localhost验证免密钥是否配置成功。
Hadoop简介
Hadoop 主要包含模块
- Hadoop Common: The common utilities that support the other Hadoop modules.
- Hadoop Distributed File System (HDFS™): A distributed file system that provides high-throughput access to application data.
- Hadoop YARN: A framework for job scheduling and cluster resource management.
- Hadoop MapReduce: A YARN-based system for parallel processing of large data sets.
hadoop支持三种启动模式:
- Local (Standalone) Mode - 单机模式
- Pseudo-Distributed Mode - 伪分布式
- Fully-Distributed Mode - 全分布式
wordcount单机测试
在单机模式下,读取的是本地数据,这里采用的是单机模式。
进入你的/hadoop目录我的是“~/app/hadoop2.6”,使用mkdir input创建一个input文件夹。随便在input目录下创建一个txt文本,准备统计文本的单词个数。
执行hadoop的统计命令:
1 | hadoop jar share/hadoop/mapreduce/sources/hadoop-mapreduce-examples-2.6.0-cdh5.7.0-sources.jar org.apache.hadoop.examples.WordCount input output |
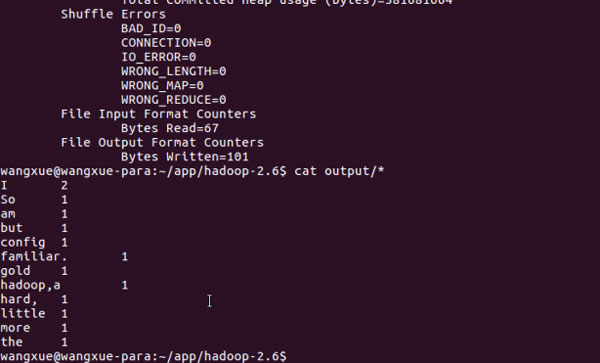
进行对单词的计数测试,然后再使用cat output/*查看计数的结果。
伪分布式
伪分布式读取的则是 HDFS 上的数据;要使用 HDFS,首先需要在 HDFS 中创建用户目录。
伪分布式里要修改hadoop的几个重要的文件。先做简单的介绍:
core-site.xml
配置公共属性,指定namenode标识以及其端口号。即确定Hadoop的核心的信息,包括临时目录,访问地址。我们用gedit编辑它。
1 | cd hadoop/etc/hadoop/ |
在configuration中添加配置property:
1 | <configuration> |
这个文件路径配置的是临时文件的地址,不配置就会在hadoop的文件夹里面生成“tmp”文件(“/home/wangxue/app/hadoop-2.6/tmp”),如果这样配置,每次重新开机启动,所有的配置就会被清空,namenode的格式化信息就会丢失,您的Hadoop环境就失效了。所以这里先建立tmp文件夹,再重新配置一个tmp文件的目录。
hdfs-site.xml
可以确定文件的备份个数以及数据文件夹的路径,即指定namenode存放元数据的位置和datanode存放数据块的位置,配置HDFS:
1 | <configuration> |
HDFS文件存储的副本个数,默认3。因为我们这只有一个节点,所以设置1.
mapred-site.xml
配置MapReduce,用于指定jobtracker标识及其端口号、指定tasktracker执行mapreduce程序的本地目录和共享目录。
1 | <configuration> |
采用yarn管理MR,还可以配置:
apreduce.jobhistory.address 历史服务器端口地址mapreduce.jobhistory.webapp.address 历史服务器web端地址
yarn-site.xml
暂时简单的理解为配置相关的job的处理,配置YARN
1 | <configuration> |
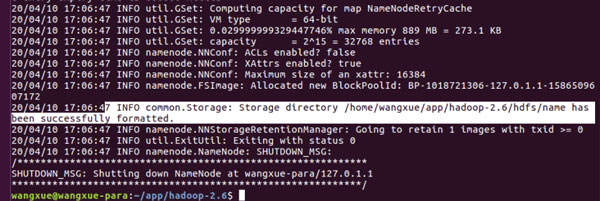
最后执行hdfs namenode –format命令来格式化hdfs。
然后依次执行hdfs的命令
sbin/start-dfs.sh,sbin/start-yarn.sh来启动hadoop。
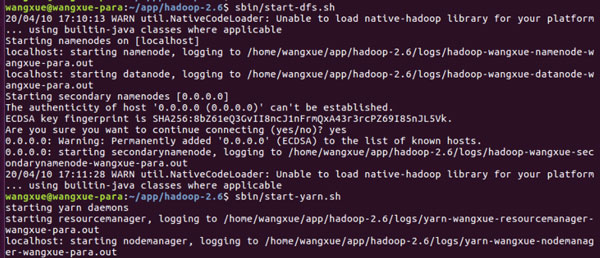
在终端输入jps发现相应的NameNode、DataNode等java进程已经在运行了。

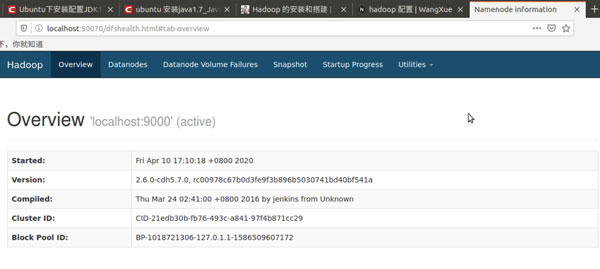
可以打开firefox浏览器,输入网址 http://localhost:50070,查看NameNode和DataNode相关信息。
检查配置是否成功,运行WordCount例子。创建输出文件夹,将txt文本文件放入input下,然后执行wordcount进行统计,最后cat展示output的结果。
1 | bin/hadoop fs -mkdir -p input |
Python执行任务
参考4,https://www.jianshu.com/p/229c7ec48110
首先我在hadoop-2.6目录下新建文件夹test/code/ ,用于存放mapper.py和reducer.py
遇到的问题:找不到hadoop-streaming,注意要找到自己本地环境中安装hadoop中的stream jar包,我的也是在share目录下的,用tab补全jar名:
1 | ~/app/hadoop-2.6/share/hadoop/tools/lib/hadoop-streaming-2.6.0-cdh5.7.0.jar |
然后上传本地的txt文件(用于统计单词的原始文本)到hdfs系统。
这里遇到一个问题是,执行到mapreduce.job: Running job **就一直卡着不动了,这里我停下了,重新jps命令检查了hadoop的启动信息,缺少了NodeManager,故重新启动了下hadoop。
1 | stop-all.sh |
jps结果如下,这个是正常的:
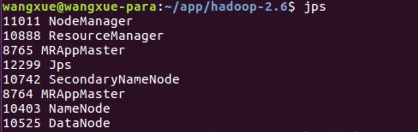
然后执行:
1 | bin/hadoop jar /share/hadoop/tools/lib/hadoop-streaming-2.6.0-cdh5.7.0.jar -file /test/code/mapper.py -mapper /test/code/mapper.py -file /test/code/reducer.py -reducer /home/hadoop/reducer.py -input /user/wangxue/hdfs_first/* -output /user/wangxue/hdfs_first_output |
正确执行:
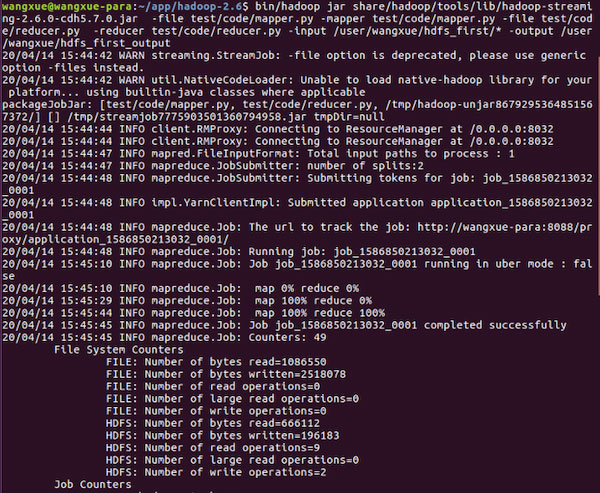
最后用cat命令查看结果
1 | bin/hdfs dfs -cat /user/wangxue/hdfs_first_output/part-00000 |
Reference
1,部分参考 http://blog.sanyuehua.net/2017/10/30/Hadoop-Pseudo-distributed/
https://blog.sanyuehua.net/2017/10/27/Hadoop-SetUp/
3,《云计算课程》实验2
4,https://www.jianshu.com/p/229c7ec48110 让Python代码在hadoop上运行

